最近、GKE Ingressで立てたロードバランサーでgRPCサーバーを公開するようなことをやったのですが、思ったよりも面倒で大変だったので備忘録も兼ねて記事化しておこうと思います。
Table of Contents
背景
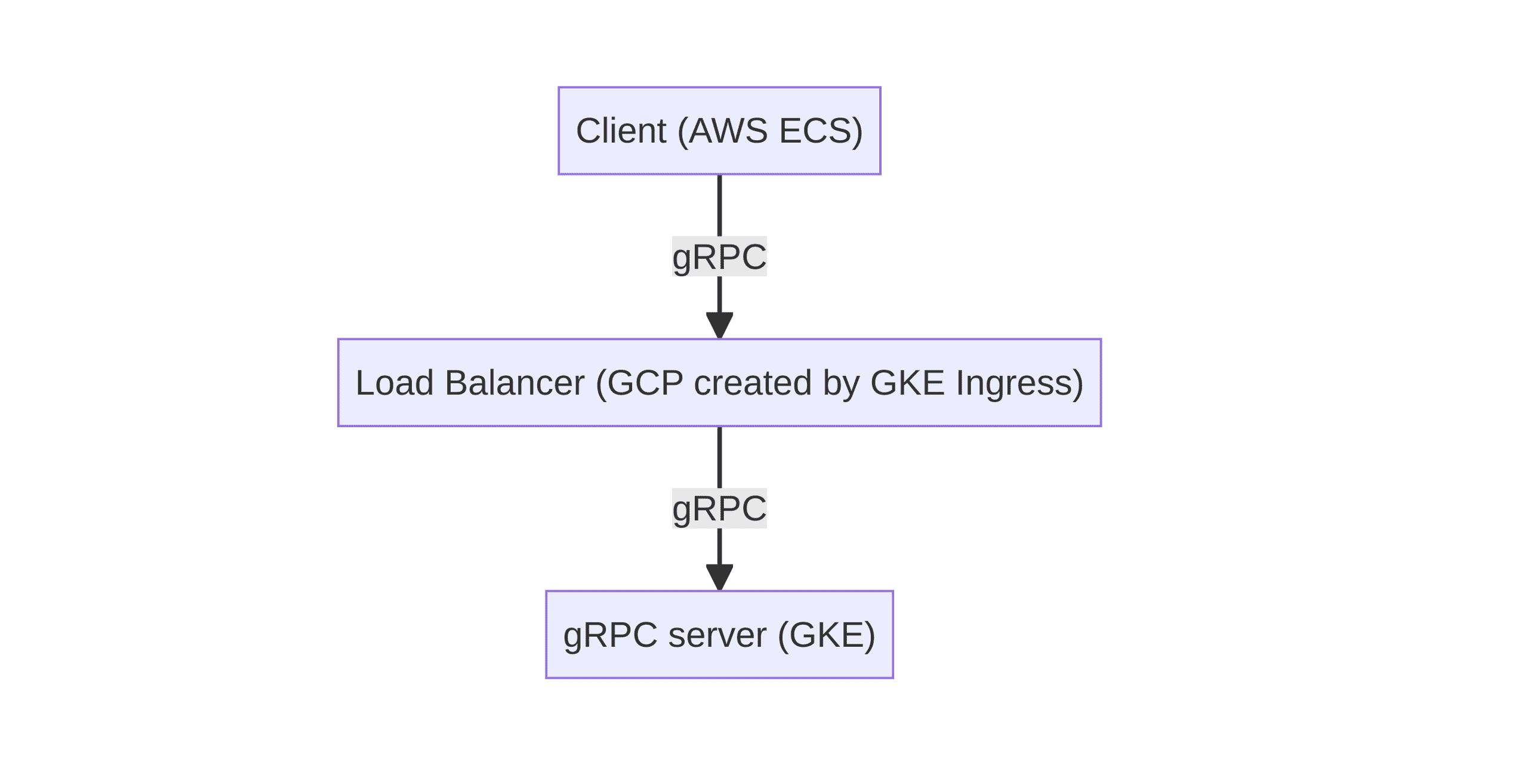
元々GKE上に構築したgRPCサーバーをgrpc-gatewayで公開していたのですが、それを直接公開することになりました(クライアント起因でHTTPにする必要があったが、その必要が無くなったため)。
できればサービスメッシュでクライアントサイドでロードバランシングするような方法を採りたかったのですが、AWS(ECS)から呼び出されるようなAPIを提供していたため、クラウドサービス間を跨いだ大規模なメッシュを構成するコストと比較して簡易になる方法としてロードバランサーで公開する方針になりました。
元々の構成
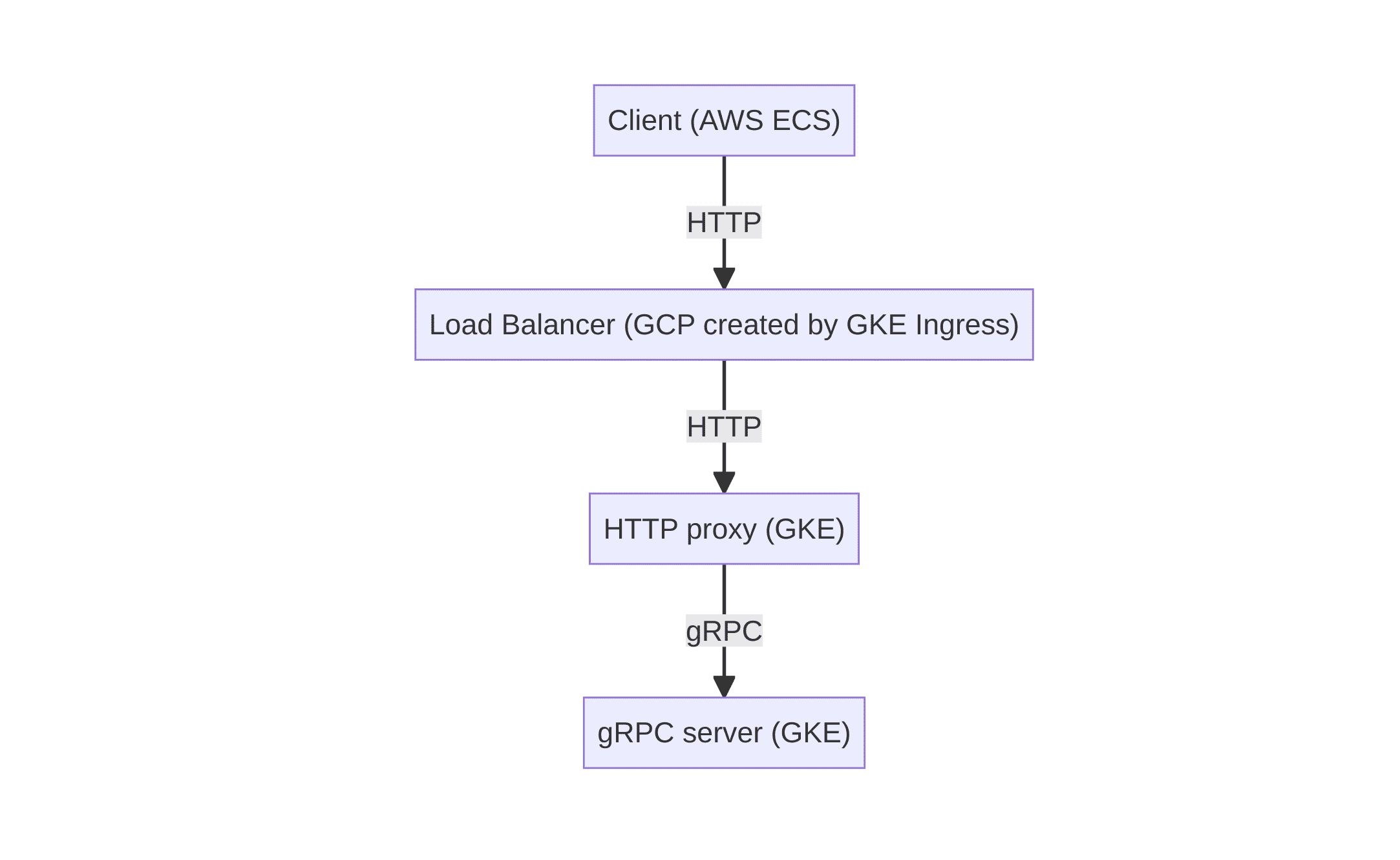
変更後の構成
ヘルスチェック問題
GCPのCloud Load BalancingはHTTP/2に対応しているため、gRPCサーバーの公開にも利用することができます。
しかし、バックエンドのヘルスチェックとしてgRPCを利用することができません。
注: Ingress は、カスタム ヘルスチェック構成に対する gRPC をサポートしていません。
https://cloud.google.com/kubernetes-engine/docs/how-to/ingress-features?hl=ja#direct_health
そのため、gRPCサーバーの稼働状況をどうにかしてHTTPで公開してあげる必要があります。
案1)nginxでルーティングを制御する
色々方法を探してみて、最初に見つけた記事はこちら。
GKE Ingress + gRPC アプリケーションのヘルスチェックをどうにかする
この記事ではnginxを用いており、ヘルスチェック用のルーティングは200を返し、それ以外はバックエンドのgRPCサーバーにパススルーしています。
やはりL7でハンドリングする方法かなーということでなるほどと思ったのですが、バックエンドの稼働状況に関わらず200を返してしまうので、商用レベルのヘルスチェックとしては不十分と考え、採用には至りませんでした。
案2)envoyのadmin用エンドポイントを公開する
続いて見つけた記事がこちら。
GKE Ingress+Envoy+gRPC で、Ingress の Health Check をクリアして構築する
envoyには、バックエンドの状態などを取得できる管理者(admin)向けエンドポイントが用意されており、それをluaで呼び出した結果を公開しようという記事です。
かなり回りくどい方法にはなってしまいますが、envoyのLuaPerRouteなど、特定パスでだけスクリプトを通す方法などなんとかなりそうだと思いこちらを検討してみることになりました。ただ、この記事の内容がかなり古いため、最新のenvoyのAPIに即した形でやってみました。
実際にやってみる
今回検証してみた内容は下記のリポジトリに上がっています。
https://github.com/ymtdzzz/envoy-grpc-health-sample
要件整理
改めて、今回の要件をまとめてみましょう。
- GKE Ingressで公開するにあたって、ヘルスチェックをクリアする必要がある
- ヘルスチェックについては、下記の形式である - HTTP/2 - 上記より、SSLによる暗号化が必要(HTTPS) - ただし、証明書の検証は行われないため自己署名証明書で良い(+内部用というのもある) - ヘルスチェック成功時は200を返す必要がある
- バックエンドの稼働状況をリアルタイムで反映する必要がある(proxyで無条件で200返すとかはNG)
ではやっていきましょう
構成
検証では下記のような構成になります。実際はClientがGKE IngressのLBになります。
- Client
- envoy proxy: ヘルスチェックとそれ以外のトラフィックをルーティングするproxy
- gRPC server: バックエンド。今回はサンプルとしてyagesを使います(シンプルなechoサーバー)
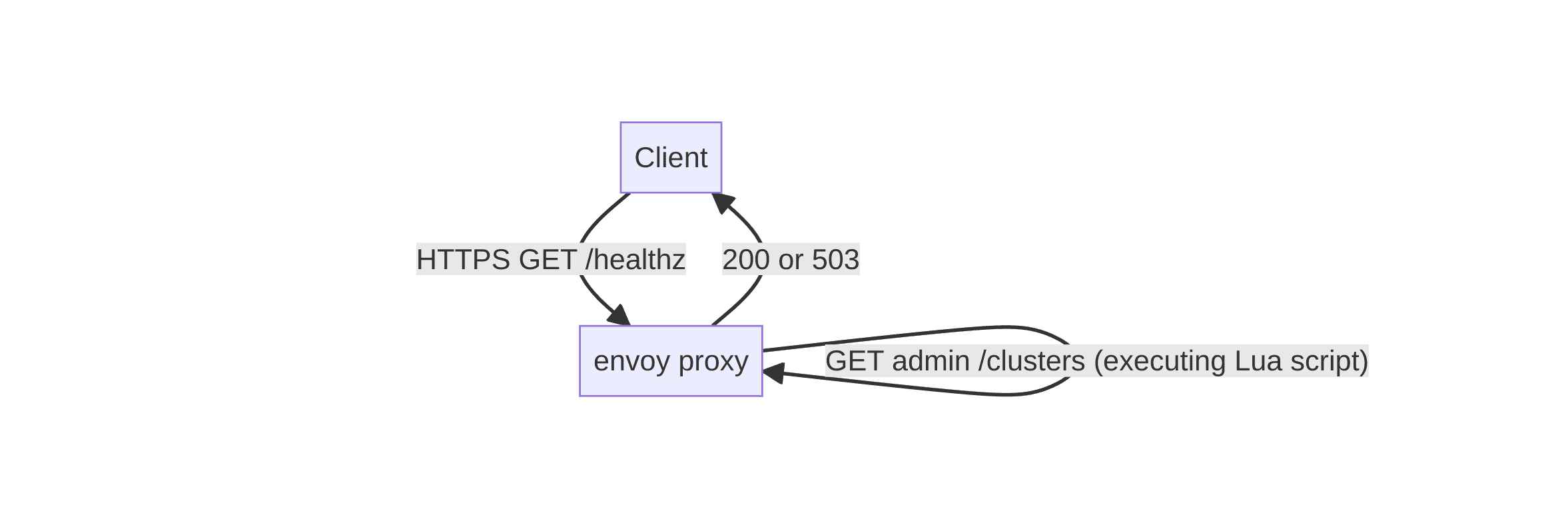
ヘルスチェックリクエスト(/healthz)が来た場合
ヘルスチェックの場合、ヘルスチェック結果をadminエンドポイントに問い合わせて結果を返却します。Luaスクリプトを実行します。
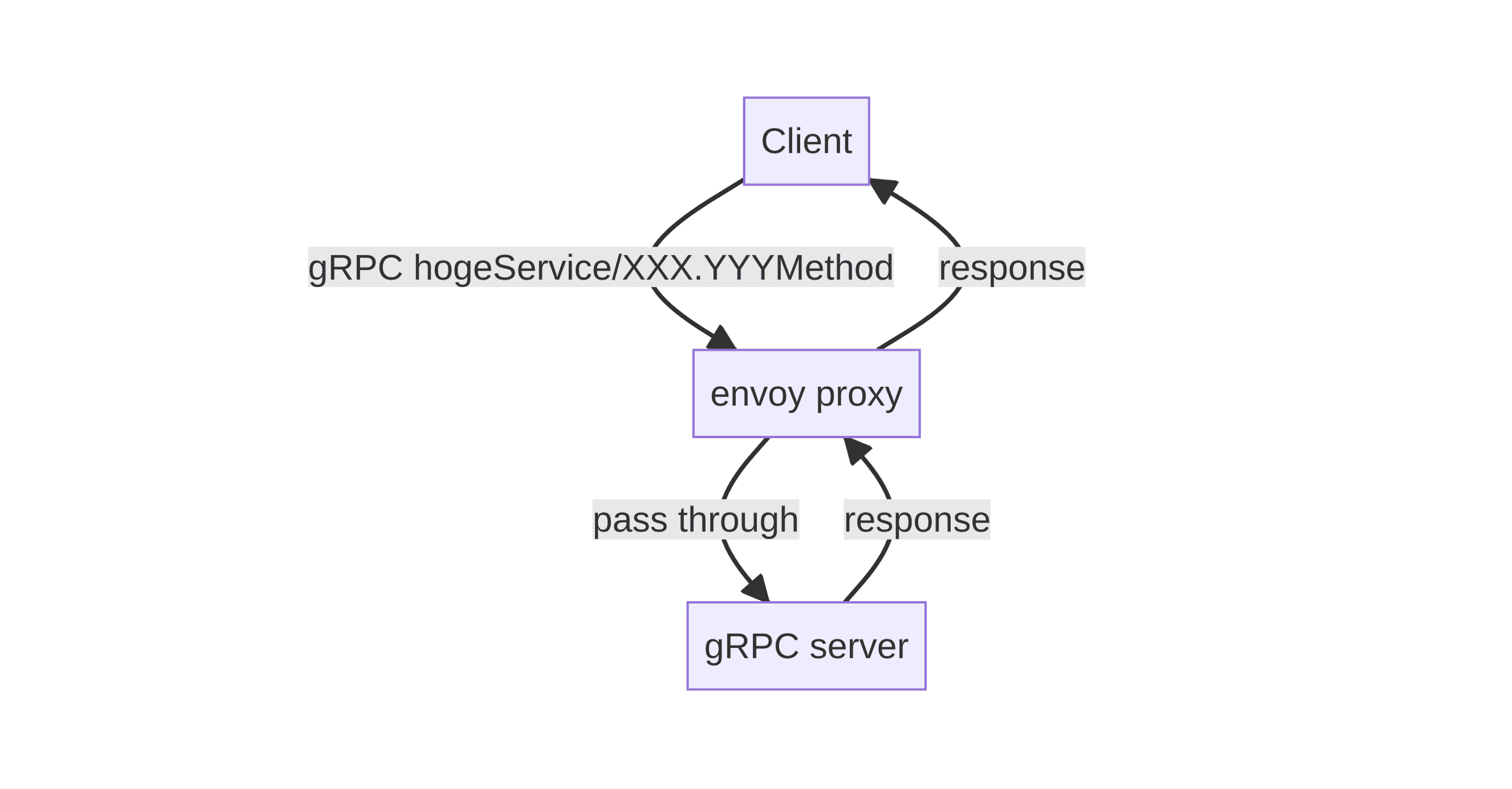
それ以外のリクエストが来た場合
それ以外の通常のリクエストが来た場合、バックエンドにリクエストをパススルーしてそのまま結果を返却します。
Adminエンドポイントとヘルスチェック
Adminエンドポイントは下記のようなconfigで有効化できます。
admin:
access_log_path: /dev/null
address:
socket_address:
address: 0.0.0.0
port_value: 8001
clusters:
- name: local_admin
type: STRICT_DNS
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: admin
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: 127.0.0.1
port_value: 8001また、バックエンドの設定とヘルスチェックは下記の通り設定できます。
clusters:
- name: my_service
type: STRICT_DNS
http2_protocol_options: {}
lb_policy: ROUND_ROBIN
load_assignment:
cluster_name: cluster_0
endpoints:
- lb_endpoints:
- endpoint:
address:
socket_address:
address: app
port_value: 9000
health_checks:
- timeout: 1s
interval: 1s
no_traffic_interval: 1s
unhealthy_threshold: 2
healthy_threshold: 2
tcp_health_check: {}no_traffic_intervalを1sに設定しておかないと、トラフィックが無い場合に稼働状況の反映が遅れてしまいます。デフォルトで60sのため、トラフィックが無い間にバックエンドがダウンした場合、最大でその反映が60s遅れてしまうことを意味します。アクセスが落ち着いてから最初のリクエストが失敗するのは許容できないため、常に1秒間隔で稼働状況をヘルスチェックに反映させます。
Luaスクリプトで/healthzでヘルスチェック状態を問い合わせ
/healthzにアクセスが来た場合、admin用エンドポイントの/clustersから稼働状況を問い合わせるスクリプトを作成します。
ちなみに、実際にadmin用エンドポイントの/clustersにアクセスするとこんな感じのレスポンスが返ってきます。
$ curl http://localhost:8081/clusters
local_admin::observability_name::local_admin
...
my_service::172.21.0.2:9000::health_flags::healthy
...curl http://localhost:8081/clusters
local_admin::observability_name::local_admin
...
my_service::172.21.0.2:9000::health_flags::/failed_active_hc/active_hc_timeout
...docker composeでapp serviceをupしたりstopしてみるとわかりますが、大体1秒程度で状態が反映されることがわかります。
Luaで実際にこのエンドポイントに対して問い合わせして結果を返却するようにするスクリプトは下記の通りです(先述のこちらの記事とほぼ同じです。)。
package.path = "/etc/envoy/lua/?.lua;/usr/share/lua/5.1/nginx/?.lua;/etc/envoy/lua/" .. package.path
function envoy_on_request(request_handle)
if request_handle:headers():get(":path") == "/healthz" then
local headers, body = request_handle:httpCall(
"local_admin",
{
[":method"] = "GET",
[":path"] = "/clusters",
[":authority"] = "local_admin"
},"", 50)
str = "my_service::%d+.%d+.%d+.%d+:%d+::health_flags::healthy"
if string.match(body, str) then
request_handle:respond({[":status"] = "200"},"ok")
else
request_handle:respond({[":status"] = "503"},"unavailable")
end
end
end先程のadmin用エンドポイントの/clustersにGETリクエストを送信し、結果にhealthyが含まれていれば200を、それ以外は503を返却するようなスクリプトになっています。
動作確認してみる
最終的なコードについてはリポジトリを参照してください(再掲)。
https://github.com/ymtdzzz/envoy-grpc-health-sample
docker composeで上げてみて、実際にapp serviceを上げたり止めたりして動作を確認してみます。
まずは動作確認用に1秒毎に/healthzにリクエストを送信し続けておきます(LBの立ち位置)。
# fish形式なので各自のシェルに合わせて実行してください
# ※-kで、オレオレ証明書の検証をスキップします
while true; curl --head -k https://localhost:8080/healthz; sleep 1; end;
HTTP/1.1 200 OK
content-length: 2
date: Sun, 23 Jul 2023 13:18:31 GMT
server: envoy
HTTP/1.1 200 OK
content-length: 2
date: Sun, 23 Jul 2023 13:18:33 GMT
server: envoy
...シェルの別セッションにて、app serviceを止め、数秒後再度docker compose up appで上げ直します。すると・・・
HTTP/1.1 200 OK
content-length: 2
date: Sun, 23 Jul 2023 13:19:35 GMT
server: envoy
HTTP/1.1 503 Service Unavailable
content-length: 11
date: Sun, 23 Jul 2023 13:19:36 GMT
server: envoy
HTTP/1.1 503 Service Unavailable
content-length: 11
date: Sun, 23 Jul 2023 13:19:37 GMT
server: envoy
HTTP/1.1 503 Service Unavailable
content-length: 11
date: Sun, 23 Jul 2023 13:19:38 GMT
server: envoy
HTTP/1.1 503 Service Unavailable
content-length: 11
date: Sun, 23 Jul 2023 13:19:39 GMT
server: envoy
HTTP/1.1 200 OK
content-length: 2
date: Sun, 23 Jul 2023 13:19:40 GMT
server: envoy
HTTP/1.1 200 OK
content-length: 2
date: Sun, 23 Jul 2023 13:19:41 GMT
server: envoy数秒間503になり、その後すぐに200に戻りました。どうやらバックエンドの稼働状況をほぼリアルタイムで反映できているようです。
実務での検証
ローカルでの検証後は、実際にk8s上にサイドカーとしてenvoyをデプロイし、container killなどでバックエンドが落ちた場合に想定通りNEGから外れてくれるかなど、実際の環境に近い形で検証を行いました。
さいごに
かなり冗長な構成になってしまいましたが、なんとかGKE Ingressで立てたLBの後ろにgRPCサーバーを配置して公開することができました。gRPC形式のヘルスチェックに対応してくれれば・・・と思うところですが、多分IstioやAnthosなど、サービスメッシュを使ってほしいということかもしれません。 (実際、今回取り上げたサービス以外で、GKE内でのサービス間通信にはTraffic Directorなどのプロダクトで簡易的なサービスメッシュを構成しています)
これまではnginxをメインで使うことが多かったですが、改めてenvoyの機能の多さに驚きました。nginxはactive healthcheckも有料版使わないとなんだよなぁ・・・。
かなりニッチな記事になっていましましたが、誰かのお役に立てば幸いです。